动态规划(百度百科)
动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。20世纪50年代初美国数学家R.E.Bellman等人在研究多阶段决策过程(multistep decision process)的优化问题时,提出了著名的最优化原理(principle of optimality),把多阶段过程转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解,创立了解决这类过程优化问题的新方法——动态规划。1957年出版了他的名著《Dynamic Programming》,这是该领域的第一本著作。
我对动态规划这个算法的理解
当初大二接触到数据结构这门课,学习了动态规划这种算法,老师一直说很难。加上自己当初上网查都是状态转移方程、重叠子问题、最优子结构。真的是让我无能为力,无从下手。每次解动态规划老想着状态转移方程怎么得到的,所以让我望而止步。最后知道了动态规划都是高度套路的之后,其实也是挺好理解的了。
动态规划的高度套路
动态规划统一都是由暴力递归–>找到有重复计算的子问题–>动态规划。
要是你要问,状态转移方程怎么来的,改暴力递归来的。动态规划就是这个一个高度套路。
示例1(斐波那契数列)
大家应该都知道这个数列,f(1)=1,f(2)=1,f(n)=f(n-1)+f(n-2)。
暴力递归写法
1 | public int fib(int N) { |
这个解法的递归展开图是这样的(以N=10举例):
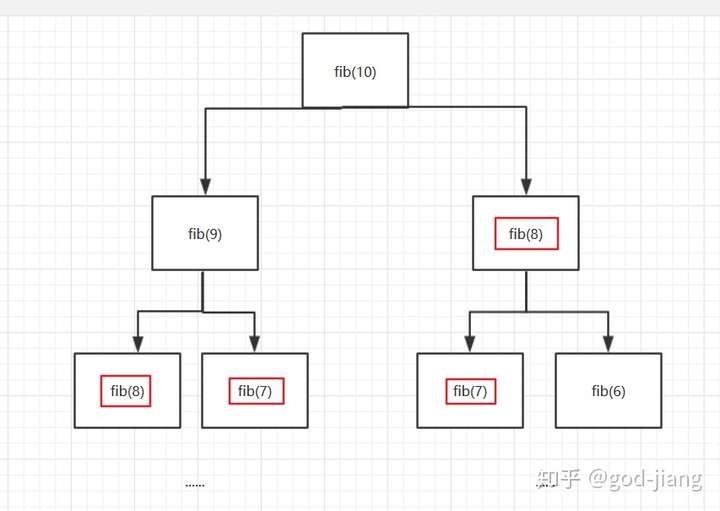
这个时候发现自顶向下的递归展开图有一些计算过程都是重复的,比如fib(8),fib(7)等,所以这样的暴力递归是可以改成动态规划的。就是改成自底向上的解法
改动态规划的步骤
- 首先找到暴力递归的base case。就是fib(1)=1,fib(2)=1
- 然后任意一个N都可以由fib(N)=fib(N-1)+fib(N-2)求出
代码(动态规划)
1 | public int dp(int N) { |
当然这个还可以优化成空间复杂度为O(1)的解法,但不在本文的讨论范围内。我们只讲暴力递归能改动态规划的套路。
示例2(最小路径和)
给定一个包含非负整数的M*N的矩阵,从左上角走到右下角的过程,使路径上的数字总和为最小。每次只能向下或者向右移动一步。
1 | 输入: |
先写暴力递归解法
1 | public int minPathSum(int[][] matrix, int i, int j) { |
这个时候的自顶向下的递归展开图是这样的(以3*3为例):
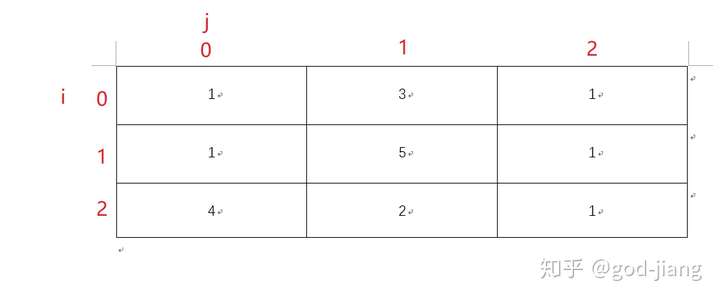
1 | 此时f(0,0)=Math.min(f(0,1), f(1,0)), |
这个时候发现自顶向下的递归展开图又有一些计算过程使重复的,可以改成非递归的动态规划自底向上的解法
改动态规划的步骤
- 先找到base case,就是最右角的值,matrix[i][j]。就是你不管用什么方法走,最后都是走到matrix[i][j],即右下角那个地方,所以那个地方就是最小值
- 然后确定了右下角的值,就可以求出最后一行和最后一列的值
- 接下来就是matrix[i][j]的值会等于它右边和下边的值的最小值
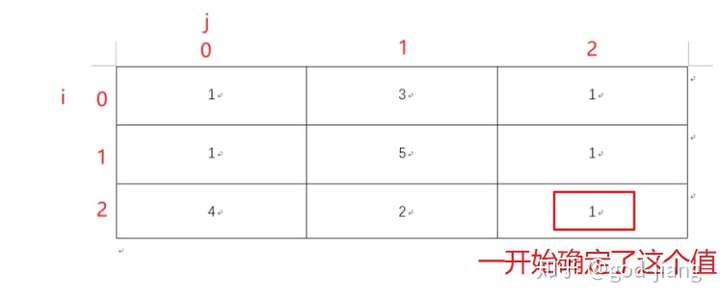
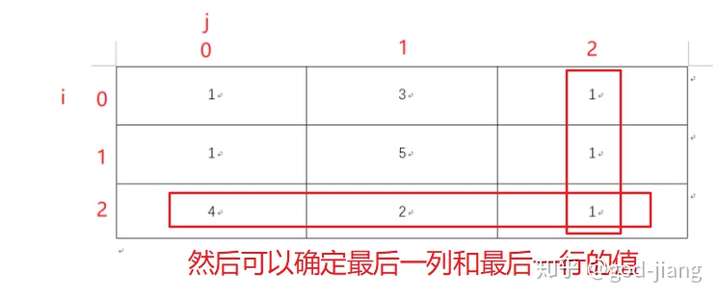
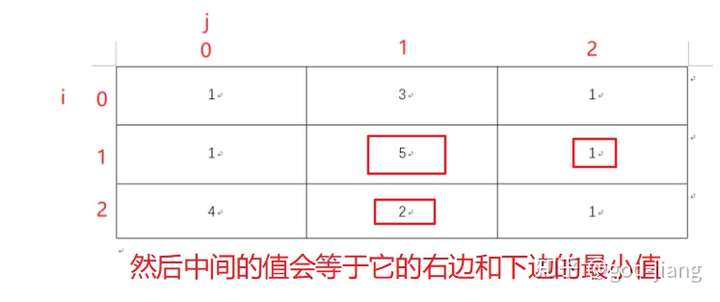
这就相当于你知道了它的base case(右下角的值),填一张二维数组的dp表,然后dp[0][0]就是左上角到右下角的最短路径
代码(动态规划)
1 | public int minPathSum(int[][] grid) { |
同样的这道题改成动态规划后可以优化成空间复杂度为O(1)的解法,但是本文就不讨论后续的优化,只讨论怎么把暴力递归改成动态规划解法。
总结
其实递归的本质就是“穷举”,然后它不知道怎么优化,它只会自顶向下无限展开,直到base case停下。然后动态规划相比于它就是自底向上计算,不会重复计算,相当于“聪明的穷举”。然后就是暴力递归改动态规划是需要有计算重复过程的时候,并且此时的状态只与以后的状态有关,和之前的状态无光,这种称为无后效性。这种可以改为动态规划。
PS:递归算法如汉诺塔问题、N皇后问题都不能改为动态规划,因为它们此时的状态与之前的状态是有联系的。因为汉诺塔需要打印出每一步的过程,而且没有重复计算,所以不能改动态规划。然后N皇后每一步下的棋都会影响到下一步,所以也不能改动态规划。
在leetcode看到大神的一个比喻:你的原问题是考出最高的成绩,那么你的子问题就是把语文考最高分,数学考最高分……为了每门课考到最高,你要把每门课相对应的选择题分数拿到最高,填空题分数拿到最高……当然,最终你的每门课都是满分,这就是最高的总成绩。
得到了正确的结果:最高的总成绩就是总分。因为整个过程符合最优子结构,”每门科目考到最高“这些子问题互相独立,互不干扰。
但是,如果加一个条件:你的语文成绩和数学成绩会互相制约,此消彼长。这样的话你能考到的最高总成绩就达不到总分了,按照刚才的思路就得不到正确的结果。因为子问题不独立,所以最优子结构会被破坏。
最后就是如果有写不对的地方可以评论或者私信我,想和我一起讨论数据结构的也可以评论和私聊我,本人非常乐意学习和进步
