背景
大学期间就自学了MySQL数据库,懂得了怎么写简单的SQL查询数据,怎么多表查询。我还一直认为MySQL也不难呀,直到工作了才知道,原来我还是太年轻了~~~
工作期间,写一个简单的CRUD就会碰到上千万的数据量,这个时候简单的select *就会花费大量的时间在查询上,这是不可容忍的。加上我公司的DBA会开启慢查询日志,还有连接接口报警,我才发现只会简单的MySQL是远远不够的,通过看书和学习总结,于是有了这篇博客。
定位慢查询
在我实际工作中,碰到某个功能或者接口需要等待很长的时间才响应的话,我们就应该去定位是不是由慢SQL导致的。一般定位慢SQL有两种解决方案:
- 查看慢查询日志确定已经执行完的慢查询
- show processlist查看正在执行的慢查询
慢查询日志
MySQL的慢查询日志用来记录在MySQL中响应时间超过参数long_query_time(单位秒,默认值10)设置的值并且扫描记录数不小于min_examined_row_limit(默认值0)的语句,能够帮我们找到执行完的慢查询。
首先开启慢查询日志,由参数slow_query_log决定是否开启,开启命令如下:

默认环境下,慢查询日志是关闭的。
设置慢查询时间阈值:

确定慢查询日志路径,慢查询日志的路径默认是MySQL的数据目录:
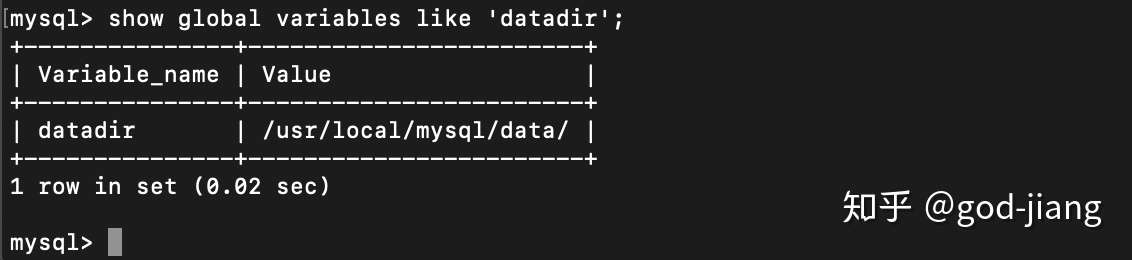
确定慢查询日志的文件名:
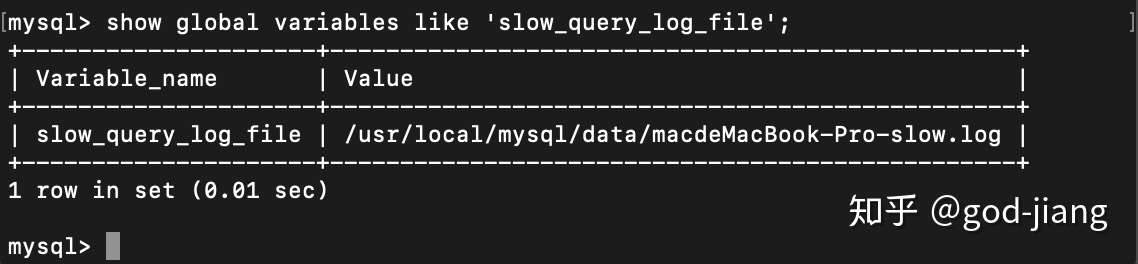
根据以上查询到的结果可以去打开文件夹查看慢查询日志。
show processlist
有时候一些慢查询已经在执行中,导致数据库负载偏高了,然后这个时候慢查询还没有执行完,这个时候查看慢查询日志是看不到任何结果的。此时可以使用show processlist命令查看正在执行的慢查询。如果由PROCESS权限,则可以看到所有线程。否则,只能看到当前会话的线程。
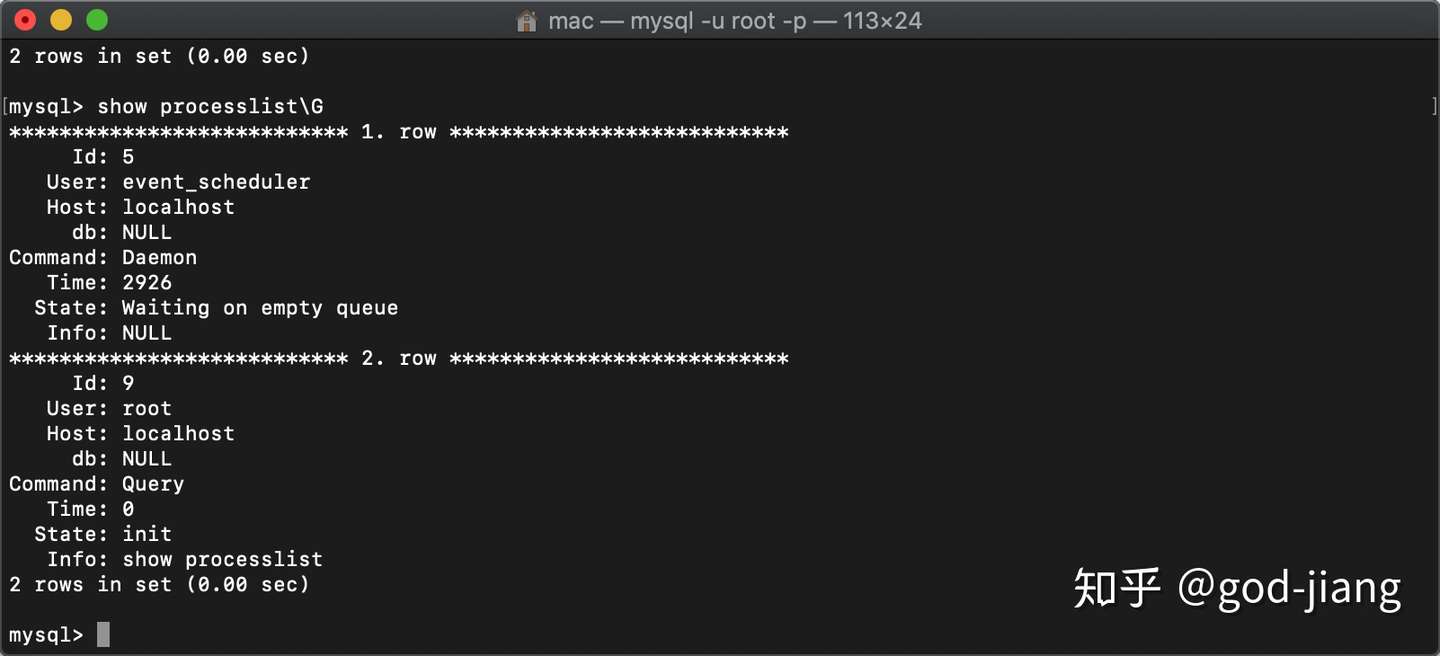
time表示时间,info表示正在执行的SQL。通过判断时间可以得知哪些SQL是慢查询。
使用explain分析慢SQL
分析SQL执行计划是优化SQL的重要手段,通过以上两种方法定位出慢查询语句后,我们可以通过explain来分析慢查询。
explain可以获取到MySQL中SQL语句的执行计划,比如语句是简单查询还是复杂查询,是否使用了索引,扫描行数等等。可以帮我们选择更好的索引。
定位表t1的结构如下所示,并且已经插入了1000条数据在t1表里:
1 | CREATE TABLE `t1` ( |
我们试着用explain来分析一下SQL的执行计划,如下所示:

explain执行后的结果参数如下所示:
| 列名 | 解释 |
|---|---|
| id | 查询编号 |
| select_type | 查询类型:简单查询或者复杂查询 |
| table | 涉及到的表 |
| partitions | 匹配的分区,仅当使用partition关键字才显示该列 |
| type | 本次查询的表连接类型 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 被选择的索引长度 |
| ref | 与索引比较的列 |
| rows | 预计需要扫描的行数,对于InnoDB来说,这个值是一个估值,并不一定准确 |
| filtered | 按条件筛选的行的百分比 |
| Extra | 附加信息 |
以上是explain对SQL生成的执行计划的参数,其中select_type,type和Extra是非常重要。
select_type各个参数解释
| select_type的值 | 解释 |
|---|---|
| SIMPLE | 简单查询(不实用关联查询或子查询) |
| PRIMARY | 如果包含关联查询或者子查询,则最外层的查询部分标记为primary |
| UNION | 联合查询中第二个及以后的查询 |
| DEPENDENT UNION | 满足依赖外部的关联查询中第二个及以后的查询 |
| UNION RESULT | 联合查询的结果 |
| SUBQUERY | 子查询中的第一个查询 |
| DEPENDENT SUBQUERY | 子查询中的第一个查询,并且依赖外部查询 |
| DERIVED | 用到派生表的查询 |
| MATERIALIZED | 被物化的子查询 |
type各个参数解释
| type的值 | 解释 |
|---|---|
| system | 查询对象只有一行数据,且只能用户MyISAM和Memory引擎的表 |
| const | 基于主键或唯一索引查询,最多返回一条结果 |
| eq_ref | 表连接时基于主键或非NULL的唯一索引晚餐扫描 |
| ref | 基于普通索引的等值查询,或者表间等值连接 |
| fulltest | 全文检索 |
| ref_or_null | 表连接类型是ref,但进行扫描的索引列中可能包含NULL值 |
| index_merge | 利用多个索引 |
| unique_subquery | 子查询中使用唯一索引 |
| index_subquery | 子查询中使用普通索引 |
| range | 利用索引进行范围查询 |
| index | 全索引扫描 |
| ALL | 全表扫描 |
查询性能由上到下越来越差。
Extra各个参数的解释
| Extra常见的值 | 解释 |
|---|---|
| Using filesort | 用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘排序 |
| Using temporary | 创建一个临时表来存储结构,通过发现对没有索引的列进行GROUP BY时 |
| Using index | 使用覆盖索引 |
| Using where | 使用where语句来处理结果 |
| Impossible WHERE | 对where字句判断的结果总是false而不能选择任何数据 |
| Using join buffer(Block Nested Loop) | 关联查询中,被驱动表的关联字段没索引 |
| Using index condition | 先条件过滤索引,再查数据 |
| Select tables optimized away | 使用某些聚合函数来访问存在索引的某个字段值 |
总结
- 分析了如何定位慢查询
- 查看慢查询日志
- show process查看正在执行的SQL
\2. explain分析慢SQL的参数信息
在工作和面试中,SQL性能优化是我们经常遇到的问题,要想做好性能优化,我们必须学会使用SQL优化时需要的工具,进行定位和分析。相信小伙伴们SQL性能优化时一定可以越来越熟练。
