背景
想象一下,你去图书馆找到一本你喜欢看的书,然后你想要快速知道这本书讲了什么内容,有哪些章节,都是通过书开头的“索引”部分,如果想要在一本书中找到某个特定主题,一般会先看书的“索引”,找到对应的页码。
在MySQL中,存储引擎用类似的方法使用索引,其先在索引中找到对应值,然后根据匹配的索引记录找到对应的数据行。接下来就来讲讲MySQL的索引吧。
索引
索引是应用程序设计和开发的一个重要方面。如果索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产生影响。要找到一个平衡点,这对于应用程序的性能至关重要。
一些开发程序员总是在开发完之后才想起来添加索引,我一直认为这是一种错误的开发模式。如果知道数据的使用会面临查询的问题,从一开始就应该在需要的地方添加索引。开发人员往往对数据库的使用停留在应用的层面,比如编写SQL语句、存储过程等。他们甚至可能不知道索引的存在,或者认为事后让DBA加上即可。DBA往往不够深入了解业务,而添加索引需要通过监控大量的SQL语句进而从中找到问题,这个步骤所需的时间肯定是远大于初始添加索引所需要的时间,并且可能遗漏一部分的索引。当然索引也并不是越多越好,会占据不必要的磁盘使用率。由此可见添加索引也是非常有技术含量的。
跟索引相关的数据结构
二叉搜索树
二叉搜索树中,左子树的键值总是小于根的键值,右子树的键值总是大于根的键值,并且每个节点最多只有两颗子树,而且最大高度差不超过1。如数据(1,2,3,5,6,7,9)在二叉搜索树的形状:
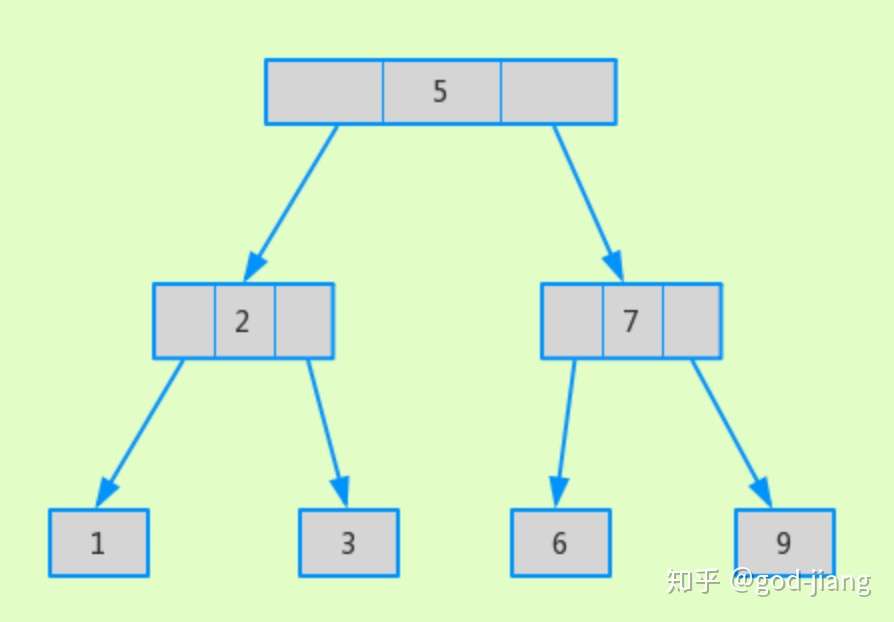
二叉搜索树查找数据的平均次数:(1 + 22 + 34)/ 7=2.4次
解释:查找次数是5只需要查找一次,2和7需要查找2次,1,3,6,9要查找3次。
但是二叉搜索树有一个缺点,每个节点只有两个分支,如果数据量大,需要遍历多层节点才能在叶子节点找到数据。
B树
B树可以理解为一个节点拥有多个分支的多叉搜索树。B树中同一个键值不会出现多次,要么在叶子节点上,要么在内节点上。如数据(1,2,3,5,6,7,9)在B树的形状:
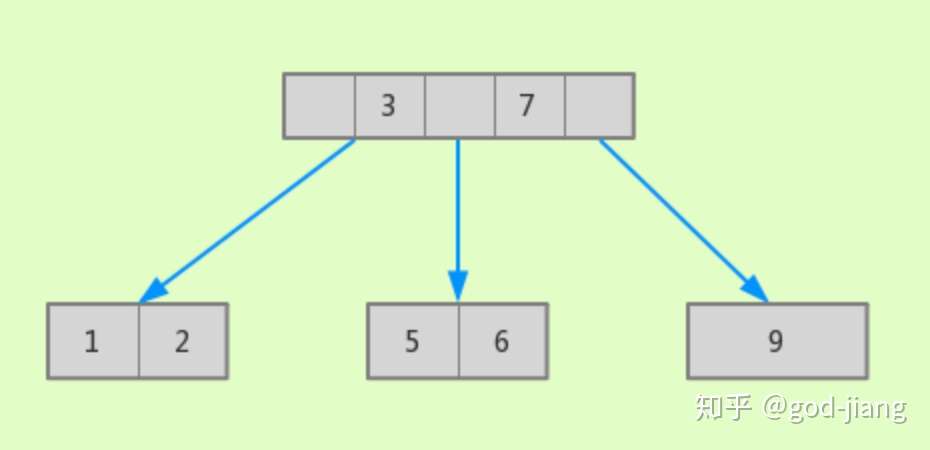
相对较于二叉搜索树,拥有了多分支,减少获取目标值所经历的节点数,提高了效率。
但是B树也是有缺点的。因为每个节点都会包含主键(key)和完整数据值(data),如果data比较大,每一页存储的key会变少;当数据比较多时,同样也会增加树的高度,需要遍历多层才能在叶子节点找到目标值的问题。
B+树
B+树是B树的变体,定义与B树基本一致,与B树不同点:
- 所有叶子节点中包含了全部关键字信息
- 叶子节点都用指针进行连接
- 非叶子节点只能存储key信息
B+树中的B不是代表二叉(binary)而是代表(balance),B+树不是一个二叉树,而是一颗多查树。
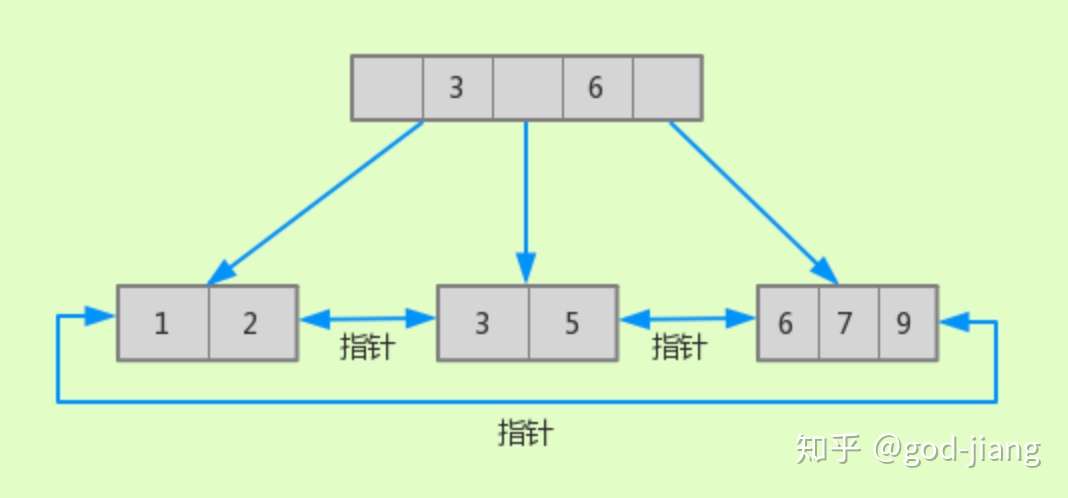
B+树的键一定会出现在叶子节点上,同时也有可能在非叶子节点中重复出现。而B树中的同一键值不会出现多次。
B+索引树
B+索引树的本质是B+树在数据库中的实现。B+树的高度一般都在2~4层,也就是说查找某一键值的行记录时最多只需要2到4次IO,这个效率就很高。因为当前一般的机械磁盘每秒至少可以做100次IO操作,2~4次的IO意味着查询时间只需要0.02~0.04秒。
数据库中的B+树可以分为聚集索引(clustered index)和辅助索引(secondary index)。但是不管时什么索引,其内部都是B+树,它们两个不同的是,叶子节点存放的是否是一整行的信息。
为了更加理解聚集索引和辅助索引,我们先建一张表。
1 | CREATE TABLE `t3` ( |
聚集索引
InnoDB的数据是按照主键顺序存放的,而聚集索引就是按照每张表的主键构造一颗B+树。
InnoDB的主键一定是聚集索引。如果没有主键,聚集索引就可能是第一个不为NULL的唯一索引,也有可能是隐藏的row id。
一般MySQL的查询优化器比较倾向于采用聚集索引,因为聚集索引能够在B+树索引的叶子节点上直接找到数据。
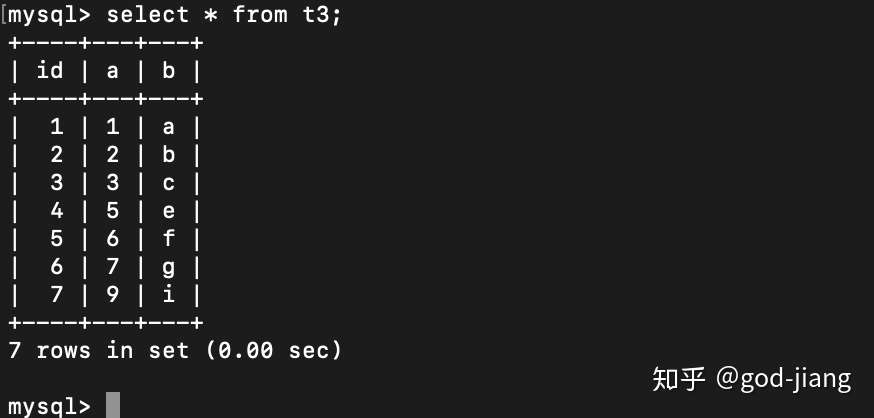
在t3表上查询所有数据:
1 | select * from t3; |
这个时候的聚集索引树就是这个样子的:
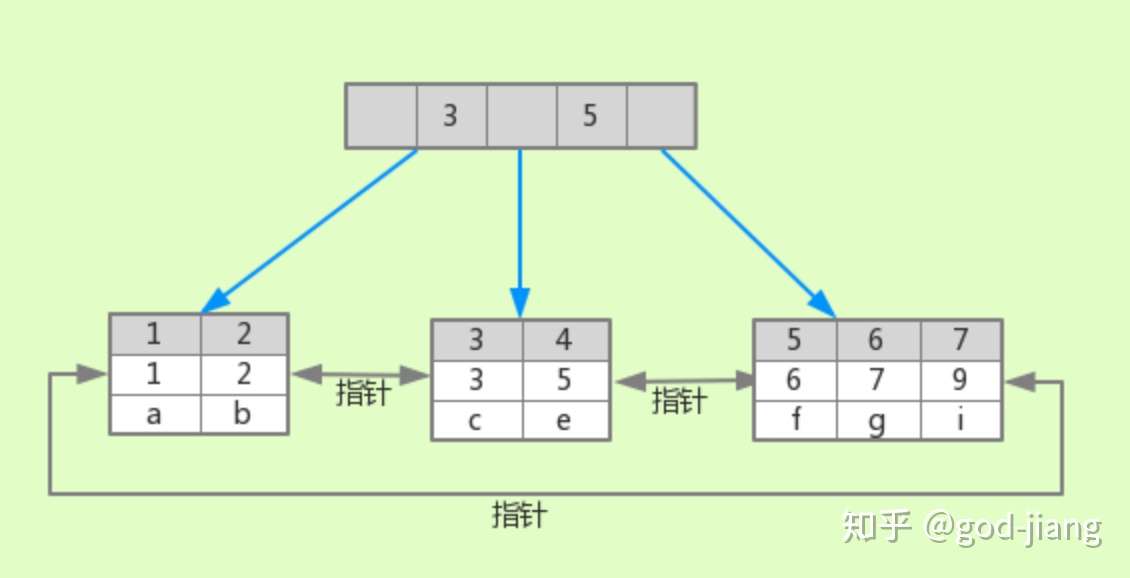
根据主键创建了B+树索引;每个叶子节点包含了整行的数据。
辅助索引
聚集索引的叶子节点存放的是整行数据,而InnoDB存储引擎的辅助索引的叶子节点并不会放整行数据,而是存放键值和主键ID。
当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引树找到对应记录的主键,然后通过主键去聚集索引树上找到对应的数据。
比如一颗高度为3的辅助索引树查找数据,需要查找3次拿到主键,如果聚集索引树也是高度为3,那么还需要对聚集索引树查找3次才能拿到对应的数据,一共进行了6次IO操作。
辅助索引在t3表是长这个样子的:
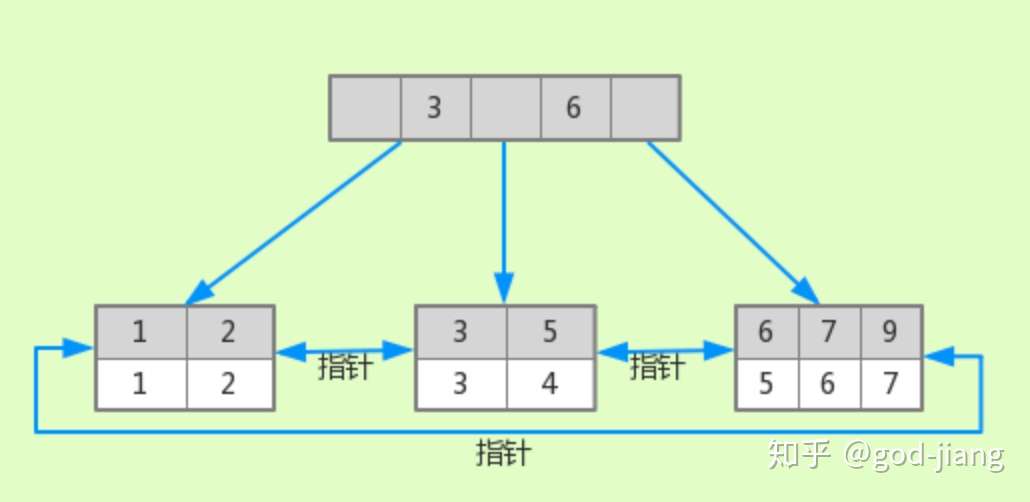
根据a字段(idx_a)创建了B+树;每个叶子节点保存的是a字段和主键ID。
通过辅助索引来查找数据:
1 | select * from t3 where a = 3; |
它是先通过a字段的索引树得到主键id为3,然后再到聚集索引树查找对应的数据。
而下面这条SQL:
1 | select * from t3 where id = 3; |
查询到的结果是一样的。但是它是直接搜索聚集索引树上的数据,比起辅助索引树减少了一次查询。所以,我们应该尽量使用主键作为条件来查询。
总结
MySQL使用最多的就是B+树索引,而B+树是由B树发展而来,我们需要了解二叉搜索树,B树的一些思想。而后面又解释了InnoDB中B+树索引的两种类型:聚集索引和辅助索引,并解释了它们在MySQL查询过程中的区别。
参考资料
- 《MySQL技术内幕》第2版 第5章 索引与算法
- 一线大厂的DBA大神经验
