背景
基本上只要是做后台开发,都会接触到分页这个需求或者功能吧。基本上大家都是会用MySQL的LIMIT来处理,而且我现在负责的项目也是这样写的。但是一旦数据量起来了,其实LIMIT的效率会极其的低,这一篇文章就来讲一下LIMIT子句优化的。
LIMIT优化
很多业务场景都需要用到分页这个功能,基本上都是用LIMIT来实现。
建表并且插入200万条数据:
1 | # 新建一张t5表 |
在翻页比较少的情况下,LIMIT是不会出现任何性能上的问题的。
但是如果用户需要查到最后面的页数呢?
通常情况下,我们要保证所有的页面可以正常跳转,因为不会使用order by xxx desc这样的倒序SQL来查询后面的页数,而是采用正序顺序来做分页查询:
1 | select * from t5 order by text limit 100000, 10; |
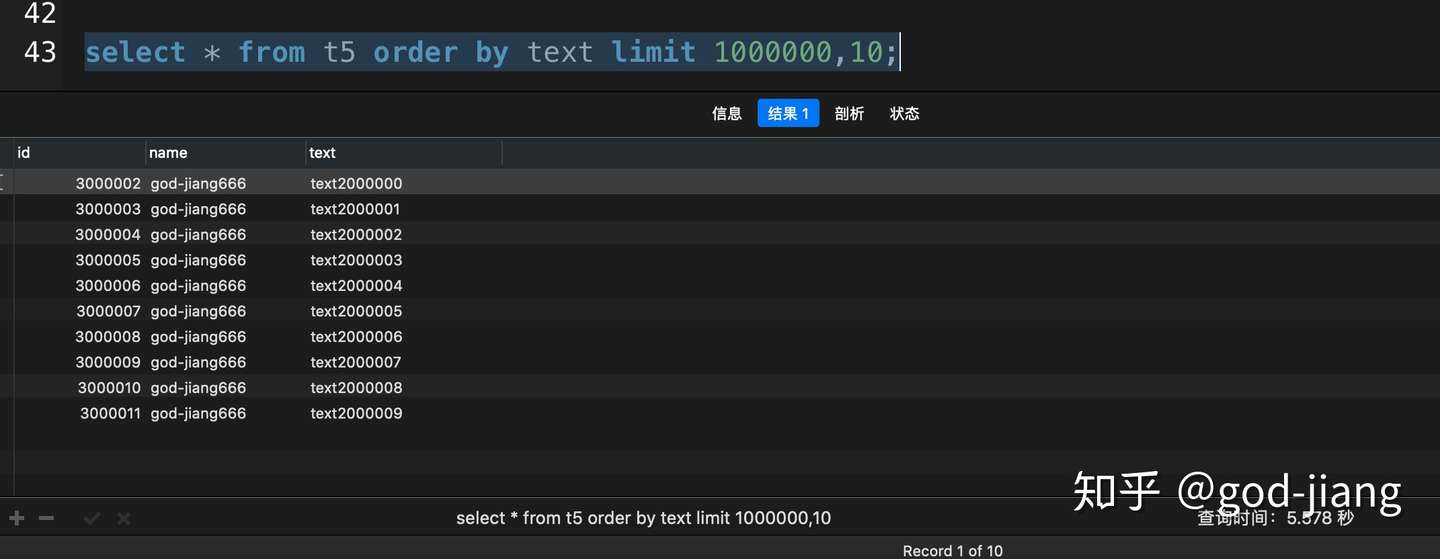
采用这种SQL查询分页的话,从200万数据中取出这10行数据的代价是非常大的,需要先排序查出前1000010条记录,然后抛弃前面1000000条。我的macbook pro跑出来花了5.578秒。
接下来我们来看一下,上面这条SQL语句的执行计划:
1 | explain select * from t5 order by text limit 1000000, 10; |
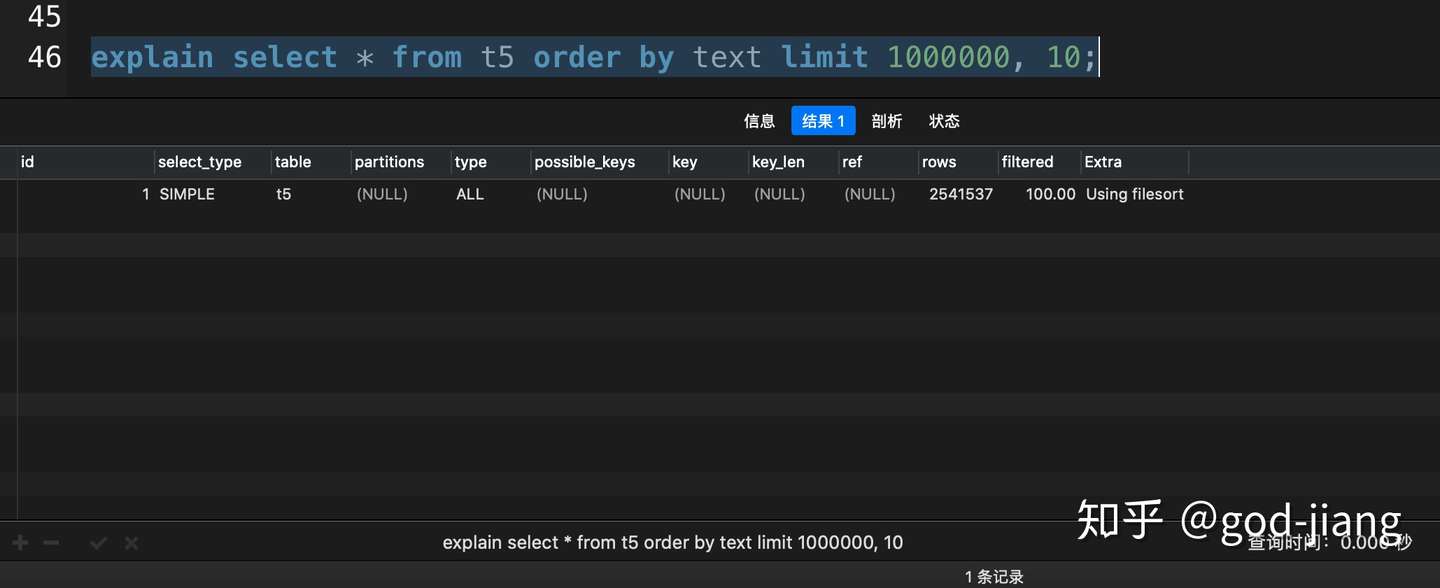
从执行计划可以看出,在大分页的情况下,MySQL没有走索引扫描,即使text字段我已经加上了索引。
这是为什么呢?
回到MySQL索引(二)如何设计索引中有提及到,MySQL数据库的查询优化器是采用了基于代价的,而查询代价的估算是基于CPU代价和IO代价。
如果MySQL在查询代价估算中,认为全表扫描方式比走索引扫描的方式效率更高的话,就会放弃索引,直接全表扫描。
这就是为什么在大分页的SQL查询中,明明给该字段加了索引,但是MySQL却走了全表扫描的原因。
然后我们继续用上面的查询SQL来验证我的猜想:
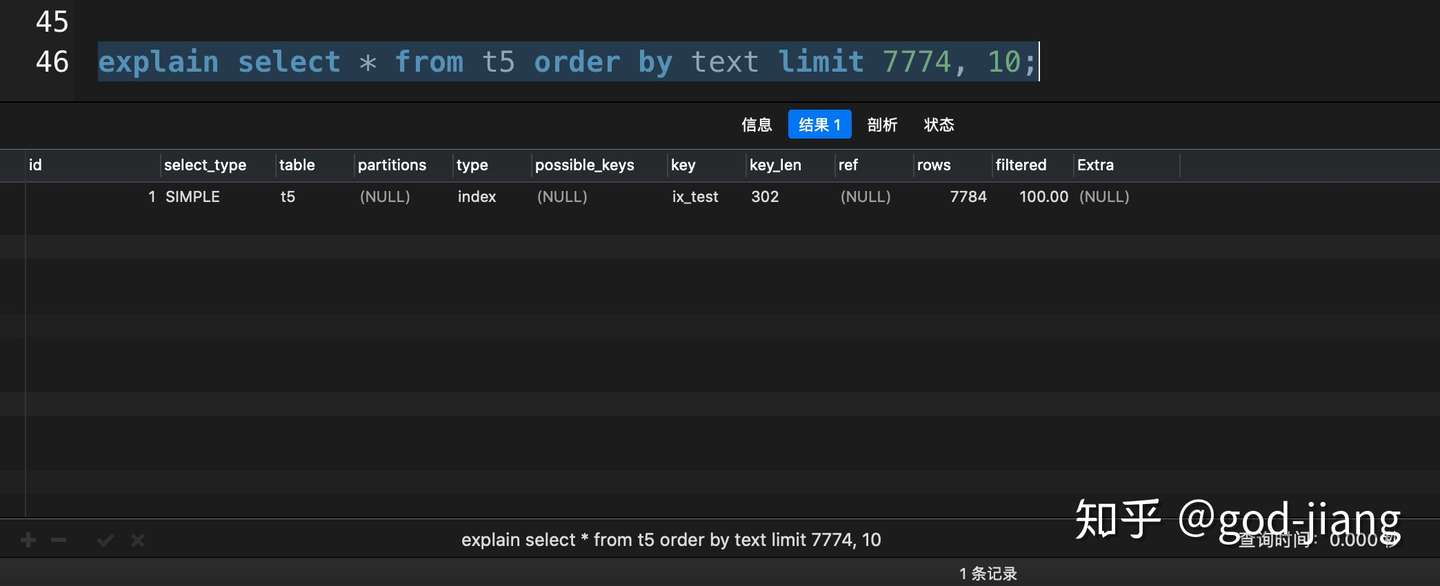
1 | explain select * from t5 order by text limit 7774, 10; |
1 | explain select * from t5 order by text limit 7775, 10; |
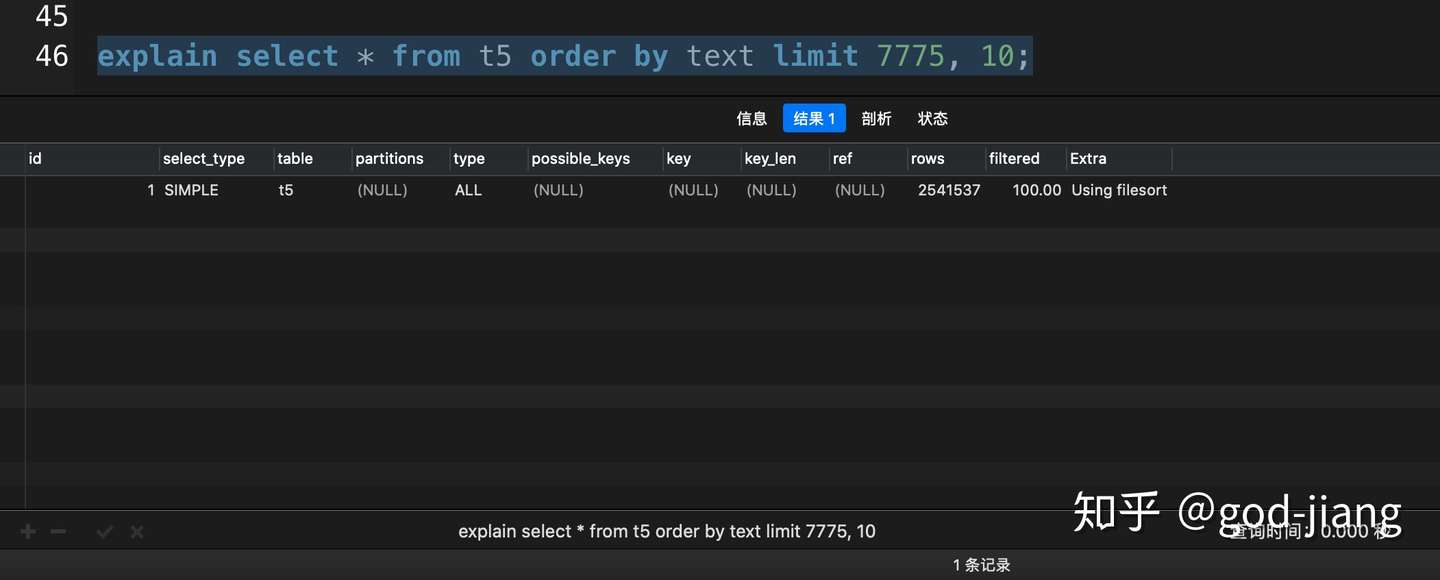
以上的实验均在我的mbp上运行的,在7774这个临界点上,MySQL分别采用了索引扫描和全表扫描的查询优化方式。
所以可以认为MySQL会根据它自己的代价查询优化器来判断是否使用索引。
由于MySQL的查询优化器的算法核心是我们无法人工干预的,所以我们的优化思路就要着手于如何让分页维持在最佳的的分页临界点。
优化方式
1、使用覆盖索引
如果一条SQL语句,通过索引可以直接获取查询的结果,不再需要回表查询,就称这个索引为覆盖索引。
在MySQL数据库中使用explain关键字查看执行计划,如果extra这一列显示Using index,就表示这条SQL语句使用了覆盖索引。
让我们来对比一下使用了覆盖索引,性能会提升多少吧。
1 | select * from t5 order by text limit 1000000, 10; |
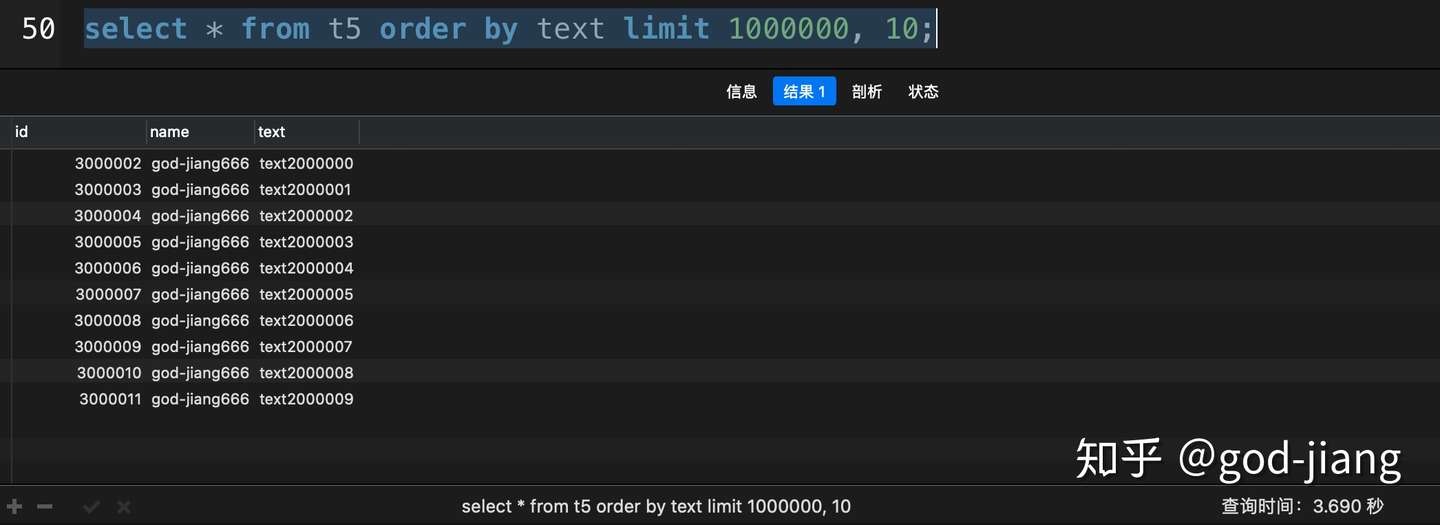
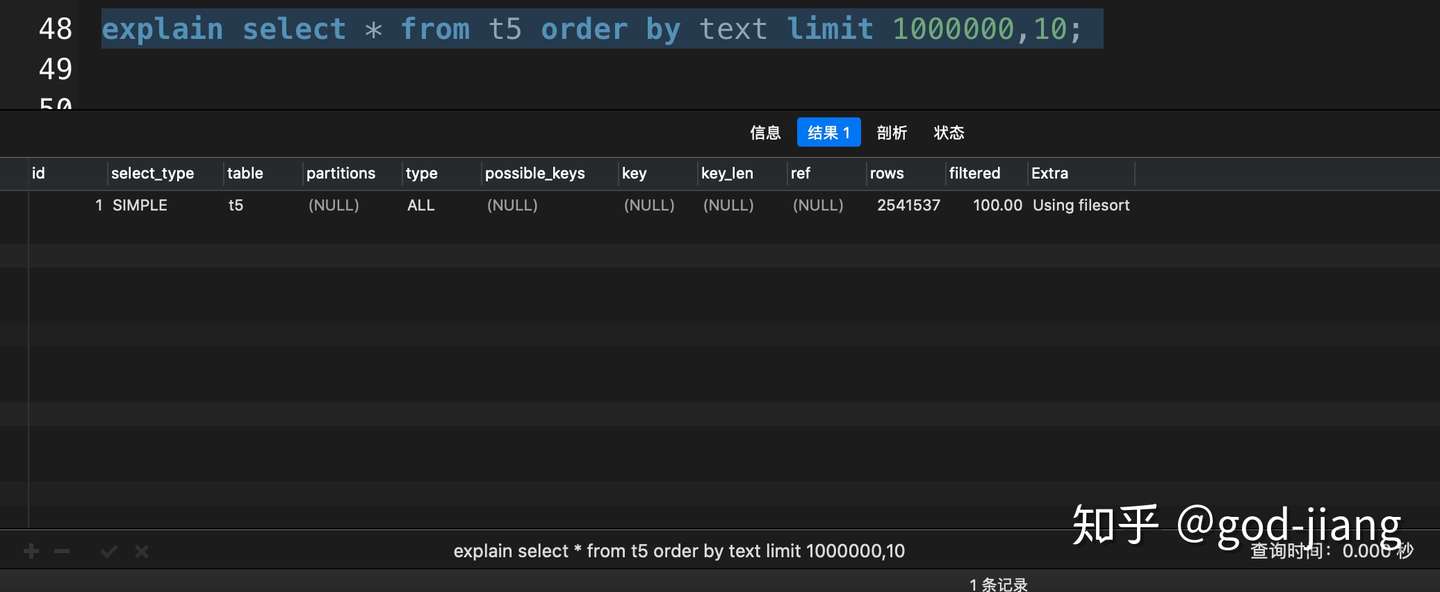
这次查询花了3.690秒,让我们看一下使用了覆盖索引优化会提升多少性能吧。
1 | select id, `text` from t5 order by text limit 1000000, 10; |
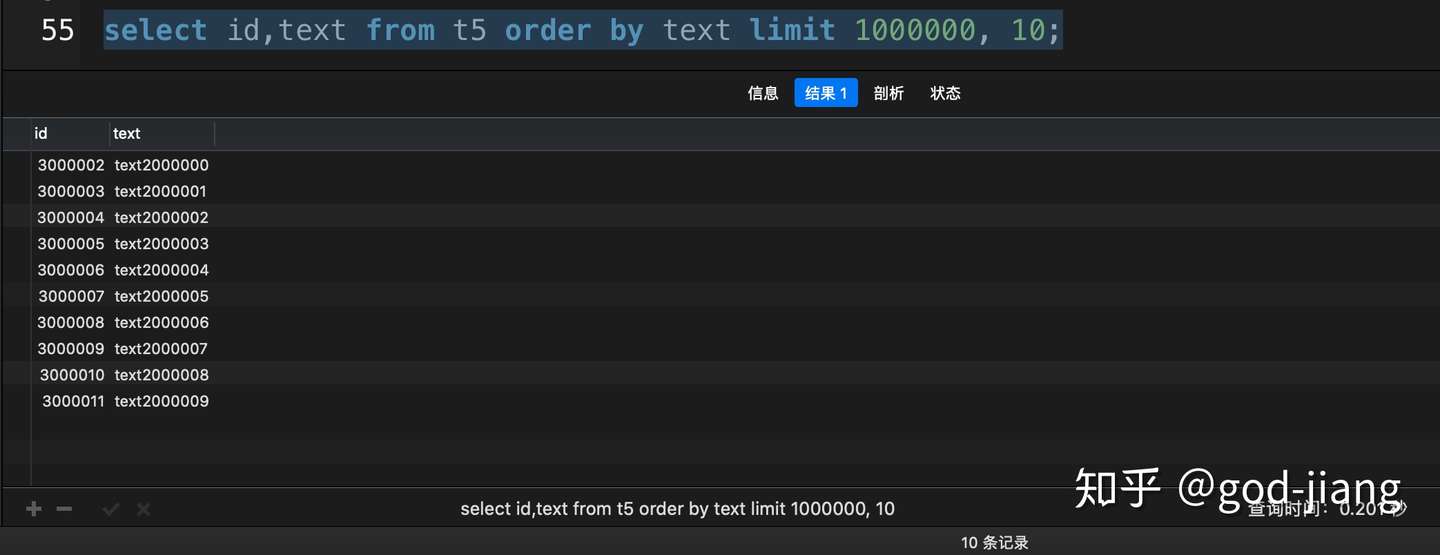
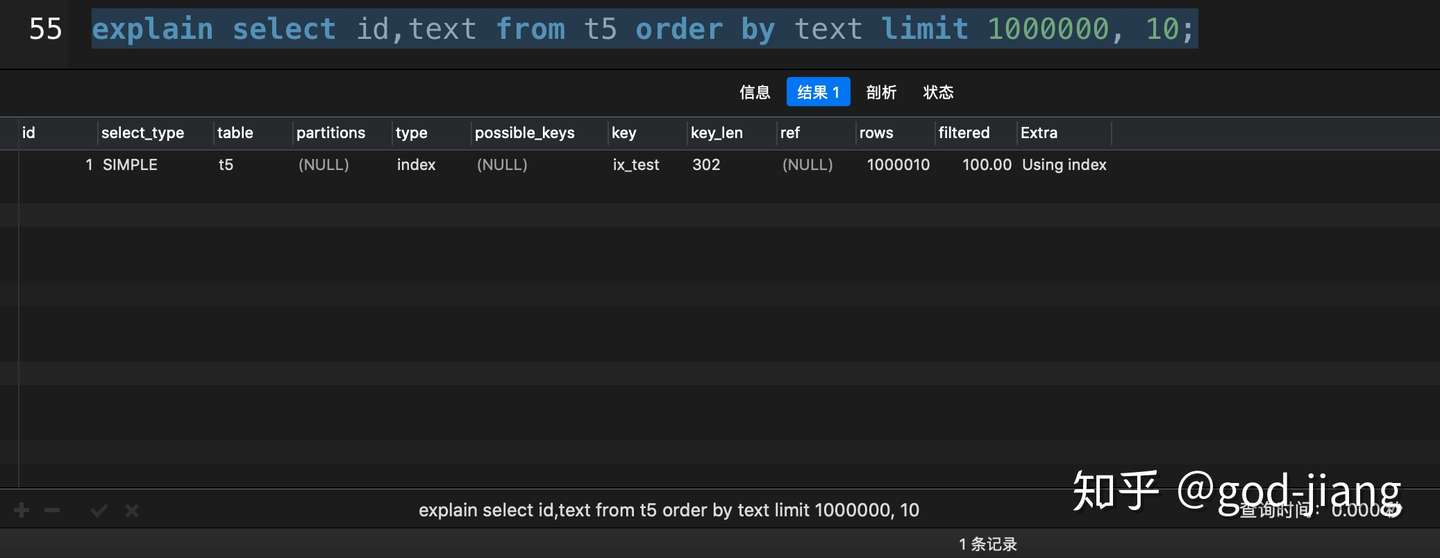
从上面的对比中,超大分页查询中,使用了覆盖索引之后,花了0.201秒,而没有使用覆盖索引花了3.690秒,提高了18倍多,这在实际开发中,就是一个大的性能优化了。(该数据在我的mbp上运行得出)
2、子查询优化
因为实际开发中,用SELECT查询一两列操作是非常少的,因此上述的覆盖索引的适用范围就比较有限。
所以我们可以通过把分页的SQL语句改写成子查询的方法获得性能上的提升。
1 | select * from t5 where id>=(select id from t5 order by text limit 1000000, 1) limit 10; |
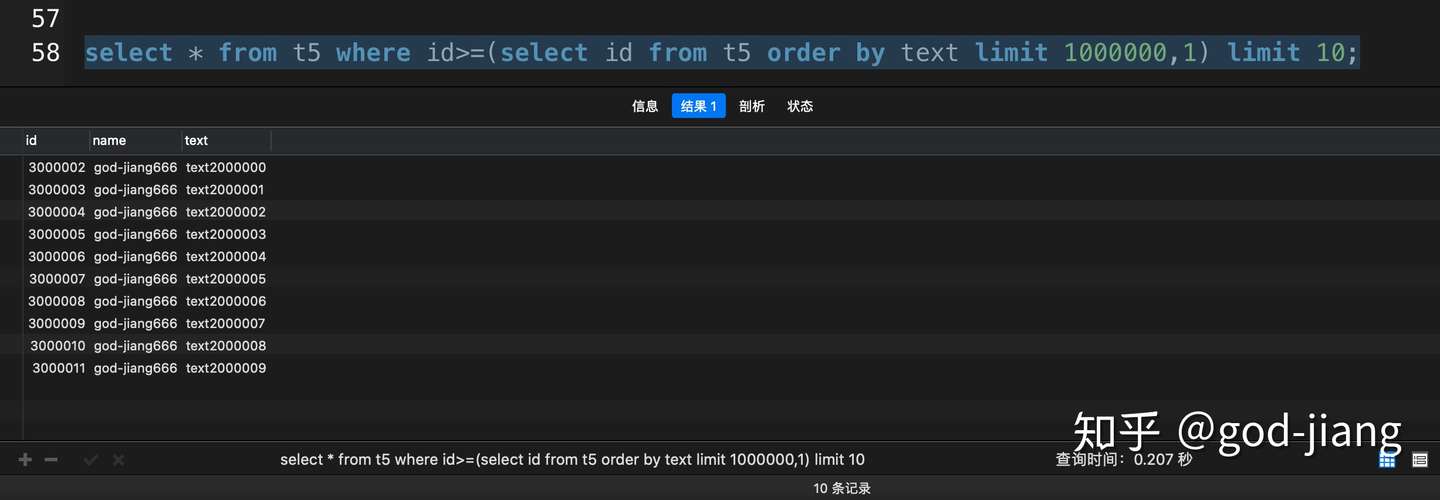
其实使用这种方法,提升的效率和上面使用了覆盖索引基本一致。
但是这种优化方法也有局限性:
- 这种写法,要求主键ID必须是连续的
- Where子句不允许再添加其他条件
3、延迟关联
和上述的子查询做法类似,我们可以使用JOIN,先在索引列上完成分页操作,然后再回表获取所需要的列。
1 | select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id; |
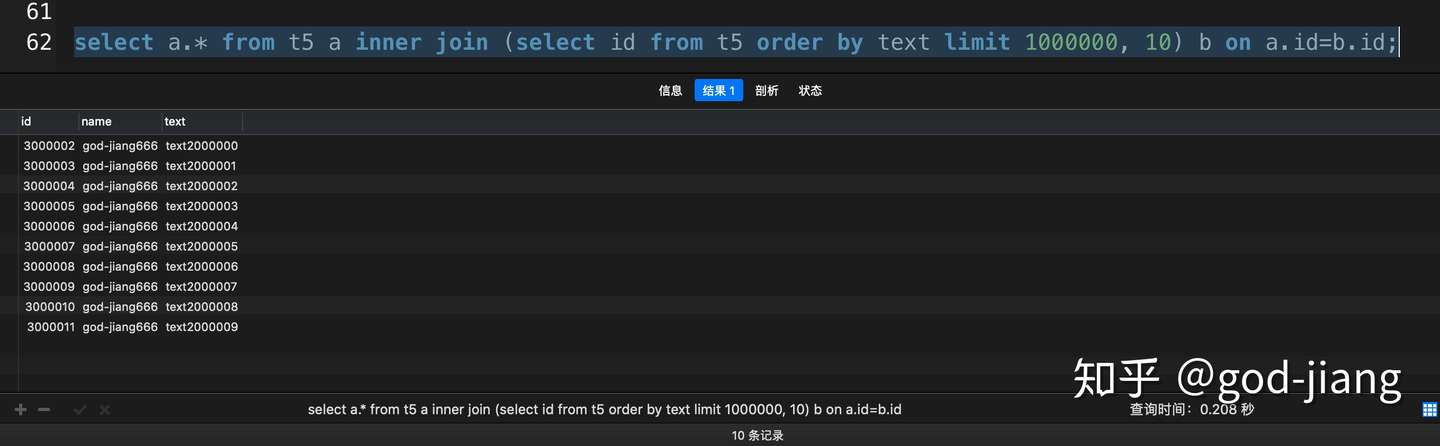
从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
4、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
1 | select * from t5 where id>=1000000 limit 10; |
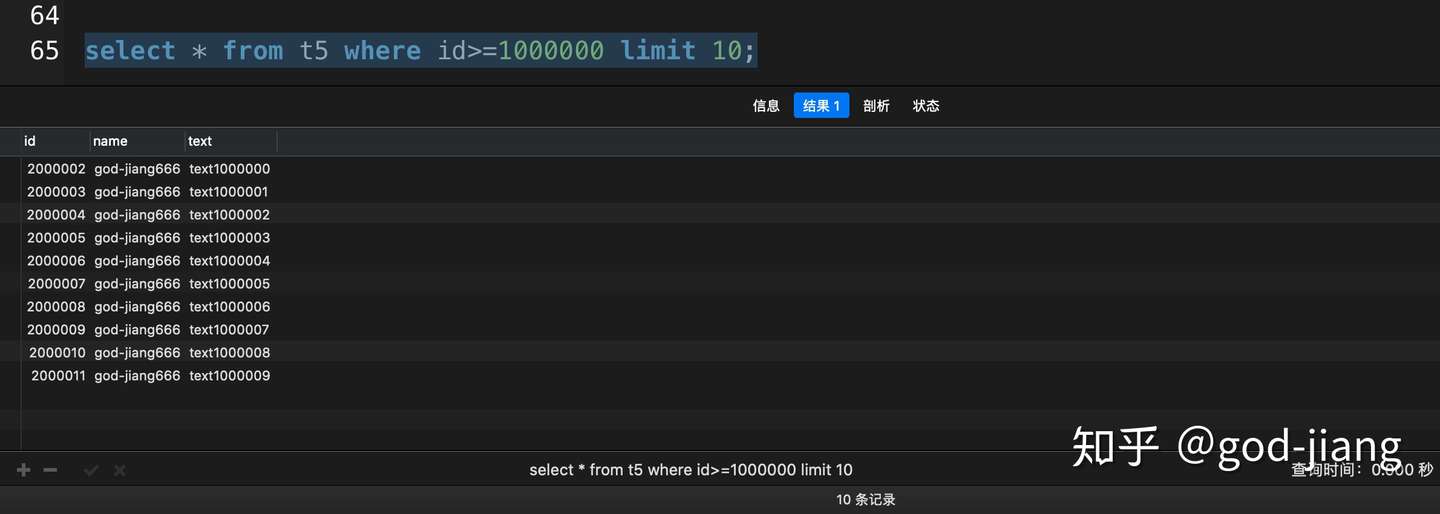
根据以上实验,不难得出,由于使用了主键索引做分页操作,SQL的性能是最快的。
总结
- 介绍了超大分页查询性能过差的原因,还有分享了几个优化思路
- 超大分页的优化思路就是让分页的SQL尽量在最佳的性能区间执行,不要触发全表扫描即可
- 希望以上的分享,可以让你们在MySQL这条路上少走弯路~~~
参考资料
- 《MySQL性能优化》第六章 查询优化性能
- 《数据库查询优化器的艺术》
