前言
在真实的企业开发过程中,有时候我们需要通过并行计算提高程序执行的性能,或者是遇到等待网络、IO响应导致耗费大量的执行时间,这些情况下我们可以通过采用异步多线程的方式来减少阻塞。这个时候我们就要学习多线程并发来实现这些业务场景。
使用线程池的好处
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗
- 提高响应速度。当任务到达时,可以不需要等待线程的创建就能立刻执行
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以统一分配、调优和监控。
JDK默认Executors提供四种线程池
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则创建线程
- newFixedThreadPool创建一个定长的线程池,可控制线程最大并发数,超出的线程会在队列中等待
- newSingleThreadExecutor创建一个单线程化的线程池,只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序进行
- newScheduledThreadPool创建一个定长线程池,支持定时及周期性任务执行
虽然以上是JDK提供给我们方便使用的线程池,但是阿里巴巴开发规范不推荐我们使用Executors创建线程池。感兴趣的可以去看看它们的源码,这里就不多赘述了。

相信看过Executors提供的四种线程池的源码就会发现,它们提供的任务队列允许的最大长度是Integer的最大值,很容易引发Out Of Memory,所以不推荐使用默认的。
那么我们要怎么样创建线程池呢?
看过Executors的源码就知道,其实JDK提供四种默认线程池都是用ThreadPoolExecutor的构造函数来实现的,所以我们自己实现也可以。
直接上源码分析一下线程池的参数。ThreadPoolExecutor有四个构造函数,其实我们只需要弄懂7个参数的构造函数就可以了(其他三种都是直接用7个参数的构造函数),让我们来看看它的构造函数吧。
1 | public ThreadPoolExecutor(int corePoolSize, |
- corePoolSize:核心线程数,初始创建的线程都是核心线程数,线程池中正常情况下始终保留该大小的线程实例存活
- maximumPoolSize:最大线程数,当核心线程都在执行任务,任务队列满的情况下会创建非核心线程来执行任务,当非核心线程处于空闲时间,且超过keepAliveTime时,会销毁非核心线程
- keepAliveTime:存活时间,用于控制非核心线程的空闲时存活时间
- unit:存活时间的单位。具体是TimeUnit枚举,有毫秒、秒、分钟、小时等等
- workQueue:线程池的任务队列,当线程池的核心线程都处于繁忙状态,且有新任务到来,则会进入任务队列,当任务队列满了,则会创建非核心线程执行新任务
- threadFactory:线程池创建线程实例的线程工厂,一般默认为Executors.defaultThreadFactory
- handler:线程池拒绝策略,当核心线程全部繁忙,任务队列已满,非核心线程全部繁忙,会触发线程池拒绝策略。默认为AbortPolicy,直接抛出异常并且拒绝。剩下还有其他三种拒绝策略可以自行去了解
线程池使用
我们现在知道了根据ThreadPoolExecutor自定义一个线程池,之后我们就需要用这个线程池来实现多线程并发编程,以下用execute和submit来演示一遍。
1 | public class TestThreadPoolExecutor{ |
执行完的结果
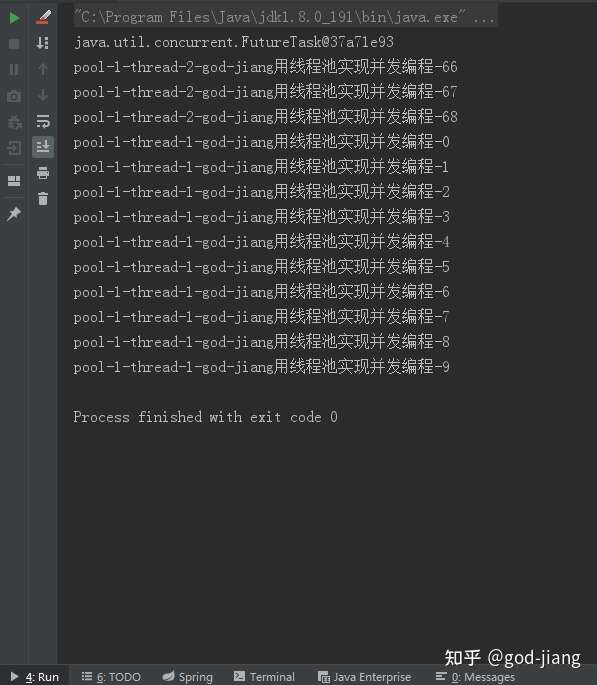
可以看到是两个不同的线程在跑任务,这就是使用JDK的ThreadPoolExecutor自定义的线程池来执行任务
总结
- 虽然使用Executors创建线程池非常方便,但是还是推荐大家少用,因为很多次生产事故都是因为Executors默认的线程池提交任务导致的
- 创建线程池必须知道每个参数的作用并且根据所负责的业务场景来实现线程池
- 请尽量使用线程池替代new Thread().start()
希望以上的分享对那些正在学习线程池的程序猿有所帮助~~~
