前言
临近春节,这段时间闲来无事又读了一些关于MySQL的文章和书籍,觉得受益良多。尤其是阿里巴巴丁奇的MySQL实战45讲,真的让我感觉到有质的提升。以前看书看博客都是优先看索引部分,优化部分。都是一些工作中常用的知识点。但现在我对MySQL的底层越来越好奇,所以从MySQL的基础架构开始学起,就有了这篇博客。
MySQL逻辑结构
大体来说,MySQL可以分为Server层和存储引擎层两部分。
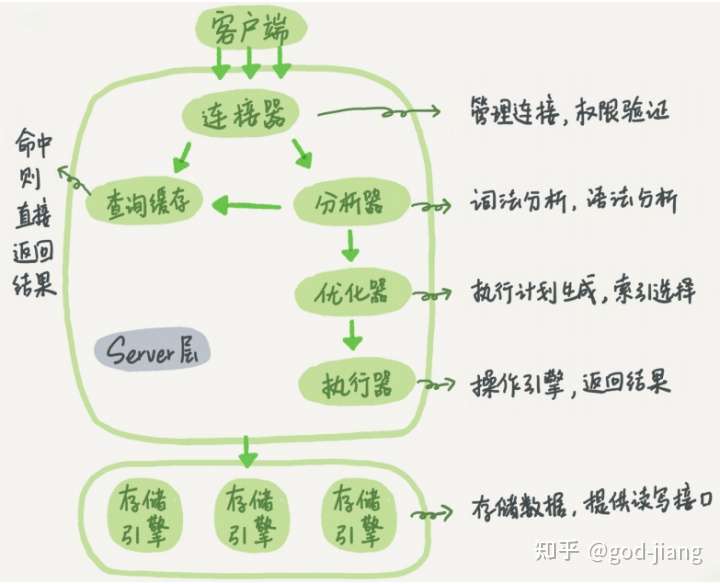
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能以及内置函数。
存储引擎层负责数据的存储和提取。它的架构模式是插件式,支持InnoDB、MyISAM、Memory等多个存储引擎。从MySQL5.5.5开始,MySQL的存储引擎默认是InnoDB。
MySQL的执行流程和组件作用
在执行这条查询语句的时候:
1 | mysql> select * from T where id = 10; |
我们只知道输入一条SQL,返回一个结果,却不知道这条语句在MySQL内部的执行过程。
接下来我会通过这条简单的查询语句,走一遍MySQL的执行流程,看一下每个组件的作用。
1、连接器
第一步,我们要先连接到这个数据库上,就先要面对连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接的作用。命令一般如下:
1 | mysql> mysql -u root -p |
输完以上命令,就要输入连接MySQL的密码。账号密码出错会受到一个“Access denied for user”的错误,需要重新连接。
mysql是客户端用来跟服务端建立连接的命令,在完成TCP握手后,连接器需要认证你的身份,这个时候就要输入账号和密码,完成连接。
连接完成后,如果没有后续的动作,这个连接就会处于空闲状态,一般太长时间没有动静,连接器会自动断开连接。这个时间由wait_timeout决定,默认时间为8个小时。
2、查询缓存
客户端和服务端建立连接后,可以执行select语句,这个时候来到了Server层的查询缓存。
MySQL在接到select请求之后,会先去查询缓存看看之前是不是执行过这条语句。之前执行过语句及其结果会以key-value存放在内存中。key是查询的语句,value是查询的结果。如果你的查询在查询缓存中找到key,则直接返回查询缓存的value给客户端。
如果查询语句不在查询缓存中,就会继续后面的执行流程。执行完成后,执行结果会被存入查询缓存中。但是在MySQL实战45讲中,作者建议我们不要使用查询缓存,为什么呢?因为查询缓存往往利大于弊。
查询缓存的失效非常频繁,只要对一张表进行更新操作,这个表的所有查询缓存都会被清空。因此你建立起来的查询缓存还没有使用就被清空了。对于更新压力大的数据库,查询缓存的命中率更低。
需要注意的是,从MySQL8.0开始,直接把整个查询缓存的功能删除掉,也就是说8.0开始没有查询缓存这个功能了。
3、分析器
如果没有命中缓存,就要开始执行查询语句。首先MySQL对你的查询语句进行解析。
分析器会先做“词法分析”。分析你的SQL,把查询语句的“T”识别成“表名T”,把“id”识别成“列id”。
做完以上识别之后,MySQL开始做“语法分析”。根据语法规则判断你输入的SQL是否满足MySQL的语法。
如果你的查询语句写错了,就会收到“You hava an error in you SQL syntax”的错误提醒。比如你的查询语句打少了一个“t”。
1 | mysql> selec * from T where id = 10; |
一般语法错误会提示第一个出现错误的位置,所以你要关注”use near”后面的内容。
4、优化器
经过了分析器,MySQL就知道了你要干什么了。在开始执行之前,还需要经过优化器的处理。
优化器是在表中有多个索引的时候,决定使用哪个索引;或者在一个SQL中有多张表联合查询的时候,决定各个表的执行顺序。比如你执行下面的语句:
1 | mysql> select * from T1 inner join T2 on T1.id=T2.id where T1.b=10 and T2.c=20; |
- 即可以从表T1取出b=10的记录值id,再根据id关联T2表,再判断T2的c等于20的记录
- 又可以从表T2取出c=20的记录值id,再根据id关联T1表,再判断T1的b等于10的记录
这两个方法执行完的结果是一模一样的,但是执行效率会有所不同,而优化器的作用是决定选择使用哪一个方法。
MySQL数据库使用的是基于成本的优化器,估算成本为CPU代价+IO代价,最后决定执行哪种方案。想更深入理解优化器,推荐你们读《数据库查询优化器的艺术》。
5、执行器
优化器阶段完成后,确定了执行方案后,就可以进入执行器阶段。开始执行语句的时候,会先判断你对这张表T有没有执行查询的权限。如果没有,就会返回没有权限的错误。
1 | mysql> select * from T where id = 10; |
如果有权限,就继续执行查询操作。执行器会根据表的存储引擎去使用引擎对应的接口。
执行过程为:
- 调用InnoDB引擎接口取表T的第一行,判断id值是否等于10,如果不是则跳过,如果是则存到结果集中。
- 调用引擎接口取下一行,重复以上的相同逻辑,直到取到表T的最后一行。
- 执行器将上面的遍历过程中所有满足id=10的行组成结果集全部返回给客户端。
到这里,语句select * from T where id = 10就全部执行完成了。
知识点串起来
以上都是一个个组件的说明和讲解,现在我把他们串起来方便大家理解。
1 | select * from T where name = 'god-jiang'; |
按照上面讲解的MySQL执行流程,这条语句的执行流程是这样的:
- 通过连接器检查当前账号是否有select这张表的权限,如果没有,就抛异常。
- 过了连接器,就到了分析器,一般SQL没有语法错误,就会继续往下走。
- 现在到了优化器,优化器会根据基于成本的优化器来决定执行哪种方案。
- 到了执行器,直接调用存储引擎的接口,然后返回结果给客户端即可。
总结
今天根据select * from T where id = 10过了一遍MySQL的执行过程和内部组件,可以让你对整个查询过程的各个阶段有个了解。
参考资料
- MySQL实战45讲 - 林晓斌
- 《数据库查询优化器的艺术》
